omneity-labs/lid-benchmark
Viewer • Updated • 27k • 90 • 2












This is super helpful, thanks! I'll get up to speed on the literature and keep your use case in mind :)
So you basically still want ASR-style transcription before the LLM kicks in (perhaps to reduce hallucination? or another purpose?), but would like the representation to be more rich so a downstream LLM can still reason about pronunciation, pauses and so on?
Hah yeah that rendering bug is for sure a meta joke (played on me :D).
Speech is for sure something I'd like to address. This work is deeply grounded in phonetics as you guessed (I wrote a paper on this topic because I love word plays https://doi.org/10.14746/linpo.2025.67.1.8 and it's kinda a precursor to this method) so it must work with audio. Just have to figure out the right way and objective.
What are the most critical gaps you see in voice AI that need an improvement?
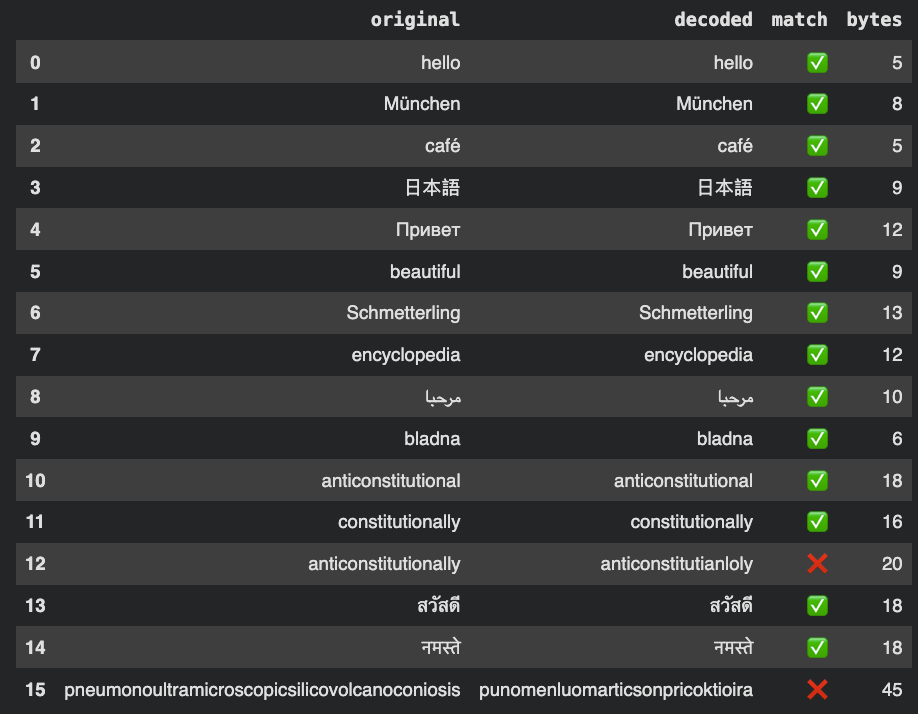
I knowww. Need to fix the video pipeline lol
Thanks @alfredo-ottomate ! In principle, it should be faster than a conventional LLM at the same scale while also using less VRAM. Mostly because it removes the softmax layer, which is one of the more expensive operations in standard language models. It also removes the embedding table, which usually accounts for roughly 10-20% of the parameters. For example, in Qwen 3.5 4B, that’s about 700M embedding parameters eliminated.
Raw performance-wise, I expect around ~10% generation speed up per-token, ~10% less VRAM usage, and better use of the context window since each token means a full word, not a subword piece.
The question then is how many parameters my replacement mechanism will ultimately need to stay competitive. The approach is already working surprisingly well at around 4M parameters, which is about 0.6% of the alternative at 4B total. Even if that number grows, the efficiency upside still looks very promising.
Fingers crossed! ✌︎
Quick update, it seems to mostly work as intended 🤯
More details here:
https://x.com/OmarKamali/status/2036932984226320748
I added a decoding head to the LLM, so the MLP generates a latent word vector that gets decoded by a GRU into a valid word.
I'm using the same input representation and train a joint encoder-decoder which gets further fine-tuned as part of the "Next Latent Prediction"(?) objective and it seems to be pretty decent for a first shot. Still working out some of the kinks.